HippoRAG: Amazon BedrockとNeptuneによる神経生物学的RAGアーキテクチャと多段階推論の深化
HippoRAGの神経生物学的インスピレーションとRAGの課題
従来のRetrieval-Augmented Generation (RAG)システムは、大規模言語モデル (LLM) の推論能力を外部情報で補強する強力な手法ですが、特に複数の情報源にまたがる「多段階推論(multi-hop reasoning)」において限界を抱えていました。従来のベクトル検索RAGは、クエリに最も類似したテキストを見つけることには長けていますが、遠く離れた文書間の関連性を結びつけることが困難であり、「トンネルビジョン」と呼ばれる課題がありました。これにより、複数の事実を連鎖させる必要のある複雑な質問に対しては信頼性が低くなる傾向がありました。
この課題に対し、HippoRAGは人間の記憶の神経生物学的プロセス、特に海馬インデックス理論 から着想を得ています。人間の脳では、新皮質が実際の記憶を保存する一方で、海馬はそれらの記憶間のポインタと連想的関係を保存する動的なインデックスとして機能します。HippoRAGは、この人間の長期記憶メカニズムを模倣することで、RAGシステムが新しい経験からより深く効率的に知識を統合することを目指しています。 その結果、HippoRAGは多段階質問応答において、既存の最先端手法と比較して最大20%のパフォーマンス向上を達成し、かつ10〜20倍のコスト削減と6〜13倍の高速化を実現しています。
HippoRAGのアーキテクチャとAmazon Bedrock/Neptuneによる実現
HippoRAGのアーキテクチャは、人間の記憶の3つの主要コンポーネントに触発されています。
-
新皮質 (Neocortex): LLMが人工的な新皮質として機能し、Open Information Extraction (OpenIE) を用いて文書から主要な名詞句やエンティティ、関係性を抽出します。 これにより、非構造化テキストから構造化された知識グラフのトリプル(例:(エンティティA, 関係, エンティティB))が生成されます。
-
傍海馬領域 (Parahippocampal Regions): 文脈の関連付けと類義語検出を担当するリトリーバルエンコーダに相当します。
-
海馬 (Hippocampus): 知識グラフとPersonalized PageRankアルゴリズムを組み合わせてインデックス作成と記憶の想起を行います。
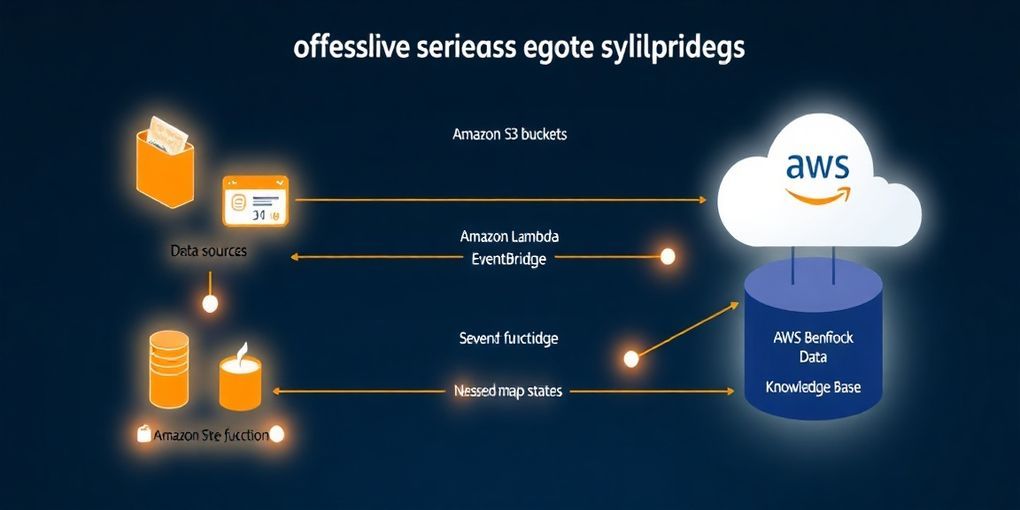
このアーキテクチャはAWSのサービス群によって具体的に実装されます。Amazon Bedrockは、LLMを活用したエンティティおよび関係性抽出、最終的な回答生成の中核を担います。 抽出されたエンティティと関係性は、Amazon Neptune、特にインメモリグラフデータ処理に特化したAmazon Neptune Analytics に知識グラフとして保存されます。このグラフでは、ノードがエンティティを表し、エッジが共起や強い意味的類似性に基づいて構築されます。 Amazon Bedrock Knowledge Basesは、Amazon Neptuneを用いた完全マネージド型のGraphRAG機能を提供し、グラフと埋め込みを自動的に生成・維持することで、開発者はグラフ技術の専門知識なしにGraphRAGアプリケーションを構築できます。
パーソナライズドPageRankによる多段階推論の実現
HippoRAGのオンライン検索プロセスは、人間の記憶の想起プロセスを模倣しています。ユーザーがクエリを発行すると、HippoRAGは単にキーワードを探すのではなく、神経活性化プロセスをシミュレートします。
-
エンティティ抽出とノード活性化: まず、LLMがクエリから名前付きエンティティを抽出し、これらのエンティティを知識グラフ内のノードにマッピングします。
-
Personalized PageRank (PPR): ここがHippoRAGの核心的な部分です。クエリに関連するノードを始点として、Personalized PageRankアルゴリズムがグラフ全体に活性化を広げます。 これは、人間の脳におけるプライミング(事前に与えられた刺激によって、その後の情報処理が変化する現象)と同様のメカニズムを模倣しており、グラフを横断して最も関連性の高いドキュメントを見つけ出します。 PPRは、孤立した検索ステップでは見落とされがちな、複数のドキュメントにわたる概念間の関係性を効率的に特定することを可能にします。
-
文書のランキングと取得: PPRによって最も強く活性化されたノードに接続されている文書が特定され、LLMのコンテキストとして取得されます。
この一連のプロセスにより、HippoRAGは従来のベクトルRAGが苦手とする多段階推論を単一ステップで実行できるという大きな利点を持っています。 これは、知識グラフとPPRが、まるで「世界観」やドメインロジックのように機能し、単なる共起ではない構造化されたスキーマに基づいて関係性を辿るため、より正確で信頼性の高い接続を発見できるためです。
開発者・エンジニア視点での考察
-
GraphRAGの導入障壁低減: Amazon Bedrock Knowledge BasesとAmazon Neptune Analyticsの統合により、専門知識なしにGraphRAGを構築できる点が開発者にとって大きなメリットです。これにより、RAGアプリケーションへのグラフ技術の導入が加速し、より高度な推論能力を持つシステムの実装が促進される可能性があります。
-
既存RAGシステムの性能向上への道筋: 従来のVector RAGが苦手とする多段階推論や関連性検出において、HippoRAGのPersonalized PageRankとナレッジグラフが顕著な性能向上をもたらすことから、既存のRAGシステムにHippoRAGの概念やコンポーネントを段階的に導入することで、システム全体のインテリジェンスとコスト効率を改善できる可能性を秘めています。
-
非構造化データからの知識グラフ自動構築: LLMを活用したOpen Information Extraction (OpenIE) による非構造化テキストからのエンティティと関係の自動抽出、およびそれに基づく知識グラフの構築は、ドメイン固有のナレッジベース構築プロセスを大幅に効率化します。これにより、開発者は煩雑な前処理から解放され、より複雑なセマンティック検索や推論機能に注力できる基盤が提供されます。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。