Amazon Bedrockナレッジベース自動同期ソリューションの構築と展開:RAGシステムの鮮度を保つ
RAGシステムのデータ鮮度課題と自動同期の必要性
検索拡張生成 (RAG) アプローチを採用するAIアプリケーションにおいて、基盤となるナレッジベースのデータ鮮度は、生成される応答の品質と関連性を直接左右する重要な要素です。情報が古くなると、LLM(大規模言語モデル)は誤った情報を提供したり、関連性の低い応答を生成したりする「ハルシネーション」のリスクが高まります。Amazon Bedrock Knowledge Basesは、このようなRAGシステムにおいてフルマネージドな体験を提供しますが、その基となるデータソースが頻繁に更新される場合、手動での同期は非効率的であり、運用上の大きな負担となります。
このような課題に対処するため、Amazon Bedrock Knowledge Basesの自動同期ソリューションは不可欠です。このソリューションは、データソースの変更を検知し、自動的にナレッジベースへの取り込み(Ingestion Job)を開始することで、RAGシステムのデータ鮮度を継続的に維持します。AWS SDKやCLIを通じて提供されるStartIngestionJob APIは、この同期プロセスをプログラムでトリガーするための主要な手段となります。
サーバーレスアーキテクチャによる自動同期ソリューション
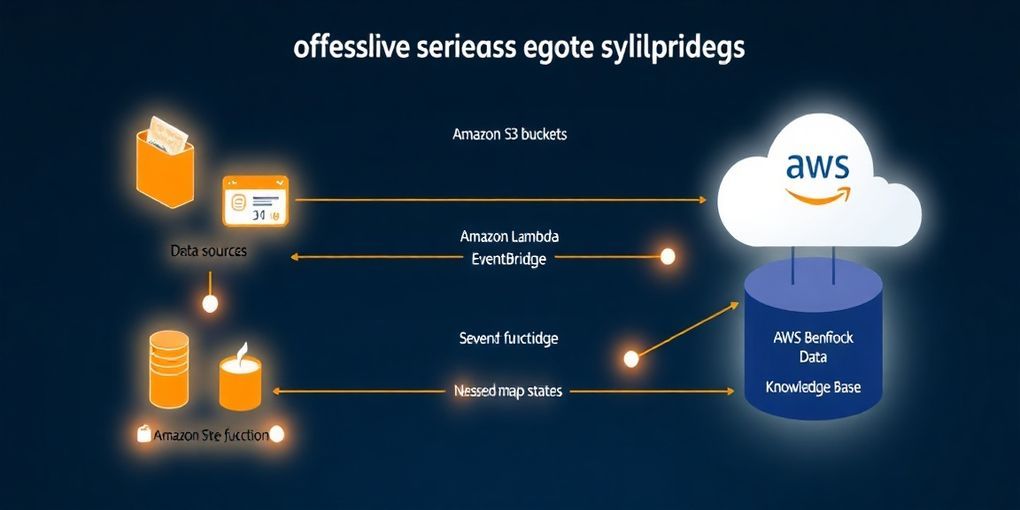
Amazon Bedrock Knowledge Basesの自動同期ソリューションは、複数のAWSサーバーレスサービスを組み合わせて構築されます。これにより、高いスケーラビリティ、可用性、および運用効率が実現されます。
主要なアーキテクチャコンポーネントは以下の通りです。
- Amazon S3: ナレッジベースの基となるドキュメントやデータが格納される場所です。S3バケットへのファイル追加、更新、削除イベントをトリガーとして利用し、同期プロセスを開始します。
- AWS Lambda: S3イベントの処理や、Step Functionsワークフローのトリガー、あるいはデータ取り込み前のカスタム変換ロジックの実行に利用されます。例えば、新しいファイルがS3にアップロードされた際に、その情報を解析してStep Functionsに渡すことができます。
- Amazon EventBridge Scheduler: 定期的な同期が必要な場合に、スケジュールに基づいて同期ワークフローをトリガーするために使用されます。例えば、15分ごとにナレッジベースのデータソース同期を試行するといった設定が可能です。
- AWS Step Functions: ソリューションの中核をなすオーケストレーションサービスです。複雑な同期ワークフローを状態機械として定義し、実行、監視、エラー処理を行います。複数のナレッジベースやデータソースを効率的に同期するために、ネストされたMapステートを活用できます。外側のMapステートで複数のナレッジベースを並行処理し、内側のMapステートで各ナレッジベース内のデータソースを順次同期するといった柔軟な設計が可能です。 Step Functionsは、
StartIngestionJobAPIの呼び出し、ジョブステータスのポーリング、結果の集約とレポート作成までを一貫して管理します。
このサーバーレスアーキテクチャにより、開発者はインフラのプロビジョニングや管理に煩わされることなく、データ鮮度を維持するためのロジックに集中できます。
実装の詳細とデプロイメントの考慮事項
本自動同期ソリューションの実装は、AWS CDKやAWS CloudFormationといったInfrastructure as Code(IaC)ツールを用いて効率的に行うことができます。これらのツールを活用することで、ソリューションのバージョン管理、再利用性、および再現性が向上します。
デプロイメントの際には、Amazon Bedrock Knowledge Basesと各AWSサービス(S3、Lambda、Step Functions)間の適切なIAMロールとアクセス許可の設定が不可欠です。これにより、各サービスが必要な操作を安全に実行できるようになります。例えば、Knowledge BaseがS3バケットにアクセスしてデータを読み取ったり、Step FunctionsがStartIngestionJob APIを呼び出したりするための権限が必要です。
技術的な詳細として、Step Functionsワークフローでは、複数のナレッジベースの処理は並列に行えますが、個々のナレッジベース内のデータソースの同期処理は逐次的に実行される点に留意が必要です。 これは、Bedrockの内部的なデータ取り込みメカニズムに起因するものであり、ワークフロー設計において考慮されるべき点です。また、同期オペレーションごとに包括的なステータスチェックと結果レポートが提供されるため、問題発生時のトラブルシューティングが容易になります。
開発者・エンジニア視点での考察
-
スケーラブルなRAGデータ管理のためのサーバーレスパターン: このソリューションは、Amazon Bedrockナレッジベースのデータ同期において、サーバーレスアーキテクチャ(S3、Lambda、EventBridge、Step Functions)がどのようにスケーラビリティと運用効率を実現するかを示しています。特に、複数のナレッジベースやデータソースを効率的に管理するためのStep FunctionsのMapステートの活用は、RAGシステムの大規模展開を検討する開発者にとって重要な設計パターンとなります。
-
データ鮮度とRAG応答品質の直接的相関: RAGアプリケーションの精度と関連性は、基盤となるナレッジベースのデータ鮮度に直接依存します。この自動同期ソリューションは、データソースの更新がタイムリーにナレッジベースに反映されることを保証し、結果としてLLMが生成する応答の品質向上に貢献します。開発者は、単にRAGを構築するだけでなく、そのデータのライフサイクル管理を自動化することの重要性を再認識すべきです。
-
拡張性とカスタマイズの余地: 提案されたアーキテクチャは、データ変換、品質チェック、エラー通知などのカスタムロジックをLambda関数やStep Functionsのステートに容易に組み込める柔軟性を提供します。例えば、データ同期の前後でデータ検証ステップを追加したり、特定のメタデータを付与する処理を挿入したりすることで、より堅牢で特定のユースケースに特化したRAGシステムを構築することが可能です。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。


