Amazon Bedrock AgentCoreで実現するビジネスインテリジェンスAIエージェント:OPLOGの事例と技術深掘り
AIエージェントによるビジネスインテリジェンス革新:OPLOGの事例分析
OPLOG社は、AIとロボティクスを活用したフルフィルメント企業であり、急速な成長に伴い、従来のBIシステムでは対応できない運用上の課題に直面していました。HubSpot CRM、コミュニケーションシステム、Microsoft Teams、Databricksといった複数のシステムにデータが散在し、データサイロが発生。これにより、包括的なBIが妨げられ、インサイトの遅延や手動レポート作成による生産時間の消費が課題となっていました。特に、週次レポートでは分析が完了するまでに機会の60%を逃すなど、ビジネス機会の損失にも繋がっていたと報告されています。
この課題に対し、OPLOGはAmazon Bedrock AgentCore上にAIエージェントをデプロイし、実稼働可能なビジネスインテリジェンス(BI)システムを構築しました。このソリューションは、数千もの日常的なビジネス取引を自律的に処理し、販売パイプライン管理、データ品質の徹底、見込み客調査にわたるリアルタイムのインテリジェンスを提供します。 結果として、セールスサイクルを35%短縮し、CRMデータ完全性を91%向上させ、手動調査時間を98%削減するという、測定可能なビジネス上のインパクトを達成しました。 このシステムは、Deal Analyzer Agent、Sales Coach Agent、Lead Insight Agentという3つの専門エージェントで構成され、それぞれが明確な目的を持って連携しています。
Amazon Bedrock AgentCoreと主要技術スタックの詳細
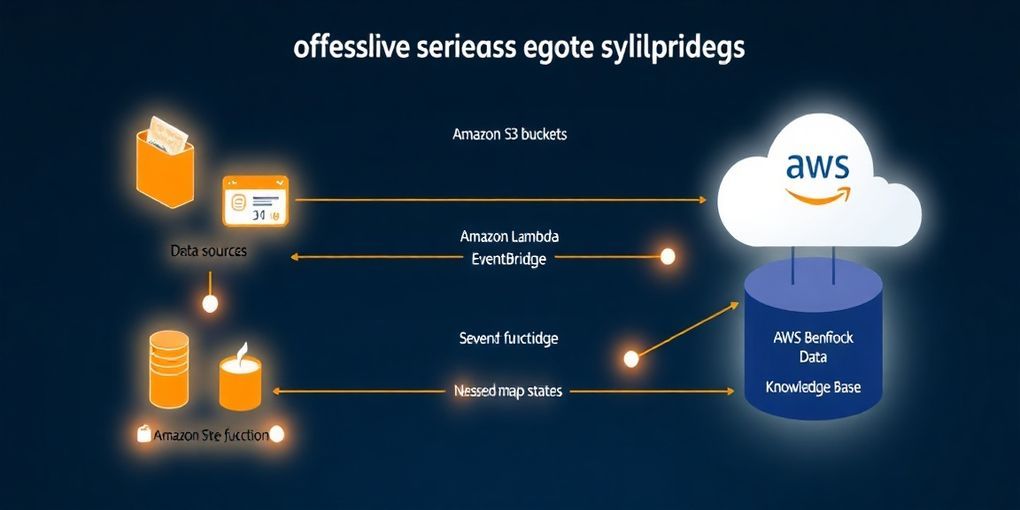
OPLOGのAIエージェントソリューションは、Amazon Bedrock AgentCoreを基盤として、複数のAWSサービスとフレームワークを組み合わせた高度なアーキテクチャを採用しています。Amazon Bedrock AgentCoreは、AIエージェントをセキュアかつスケーラブルに構築、デプロイ、運用するためのマネージドプラットフォームであり、インフラ管理のオーバーヘッドを排除します。
エージェントの主要な技術スタックは以下の通りです。
- 推論エンジンとしてのAmazon Bedrock: エージェントの「脳」として機能し、OPLOGの事例ではAnthropicのClaude Sonnetが採用されました。このモデルは、データ分析、複雑なビジネスルールの推論、および実用的なインサイトの生成を担います。
- RAGによるコンテキスト強化 (Amazon Bedrock Knowledge Bases): 営業プレイブック、製品カタログ、メソッド文書など、Amazon S3に保存された膨大な非構造化データから関連情報をエージェントが検索し、意思決定に活用できるようにAmazon Bedrock Knowledge Basesが実装されています。 エージェントは自然言語で知識ベースにクエリを実行し、取得されたコンテキストをAnthropic Claudeが適用して、各取引段階やビジネスモデルに応じた適切な検証ルールを決定します。
- エージェント開発フレームワーク (Strands Agents SDK): エージェントの動作定義、カスタムツールの作成、統合ポイントの確立には、Strands Agents SDKが使用されています。 これは、エージェントをコードファーストで構築するための柔軟なフレームワークです。
- セキュアな実行環境 (AgentCore Runtime): AgentCore Runtimeは、動的なAIエージェントとツールをデプロイ・スケーリングするための基盤となる、セキュアでサーバーレスな環境を提供します。 ワークロードに応じてゼロから数千セッションへと自動的にスケーリングし、デプロイの更新もダウンタイムなしで行われます。
- コード実行能力 (AgentCore Code Interpreter): エージェントがデータ処理、ロジック検証、ビジュアライゼーション作成のためにソフトウェアコードを実行する必要がある場合、AgentCore Code Interpreterがセキュアなサンドボックス環境を提供します。 これにより、複雑な計算やデータ分析を高い精度で実行できます。
- ウェブ操作機能 (AgentCore Browser Tool): ウェブサイトのナビゲーションやオンラインフォームの入力など、ウェブを介したインタラクションを含むワークフロー向けに、高性能なクラウドホスト型ブラウザを提供します。 AWSによって管理され、アンチボット保護も処理し、エージェントの呼び出しに合わせて自動的にスケーリングします。
- 記憶管理 (AgentCore Memory): エージェントのコンテキストを複数のインタラクションにわたって維持するためのフルマネージドサービスです。 短期記憶(マルチターンの会話)と長期記憶(セッションを超えた知識やインサイトの保持)をサポートし、エージェントが経験から学習し、意思決定を改善することを可能にします。
- 外部システム連携 (AgentCore Gateway): 既存のAPIやLambda関数などをModel Context Protocol (MCP) 互換のツールに変換し、セキュアな認証・認可フローを管理しながら、サードパーティサービスとの連携を簡素化します。
スケーラビリティ、セキュリティ、運用への影響
Amazon Bedrock AgentCoreは、エンタープライズレベルでのAIエージェント導入におけるスケーラビリティ、セキュリティ、運用効率の課題を根本的に解決します。
- 卓越したスケーラビリティとコスト効率: AgentCore Runtimeのサーバーレスアーキテクチャは、何千ものセッションにわたる動的なワークロードに自動的に対応し、OPLOGの事例では数千の日常的なビジネスイベントを処理しながら99.9%のアップタイムを実現しました。 従来のインフラと比較してインフラコストを大幅に削減し、高度なAI駆動型BIをアクセスしやすく、スケーラブルにします。
- エンタープライズグレードのセキュリティとガバナンス: AgentCoreは、セッションの隔離、VPCサポート、AWS Identity and Access Management (IAM) やOAuthに基づくID管理を提供し、金融サービスなどの厳格なセキュリティ要件に適合します。 さらに、「Policy in Amazon Bedrock AgentCore」機能により、自然言語やCedar(AWSのオープンソースポリシー言語)を使用して、エージェントがアクセスできるツールやデータ、実行できるアクション、およびその条件を明確に定義し、不正なアクションをリアルタイムでブロックできます。
- 運用効率と開発サイクルの短縮: AgentCoreは、AIエージェントの「Deploy, Enhance, Monitor」ライフサイクルを標準化することで、カスタムのDevOps作業に要する数ヶ月間の労力を不要にします。 また、AgentCore Evaluationsは、エージェントの行動に基づいて品質を継続的に検査するための13の事前構築済み評価器を提供し、開発者は独自の評価器をカスタマイズすることも可能です。 これにより、AIエージェントのプロトタイプから本番環境への移行が大幅に加速され、チームはインフラ管理ではなく、エージェントのビジネスロジックと価値の創出に集中できるようになります。
開発者・エンジニア視点での考察
-
フレームワーク・モデル非依存性による技術選択の自由度: Amazon Bedrock AgentCoreは、Strands Agents SDKだけでなく、LangGraph、CrewAI、LlamaIndexといった主要なオープンソースフレームワークをサポートし、Amazon Bedrock上の基盤モデルだけでなく、OpenAI、Google Geminiなど、OpenAI互換のあらゆるモデルプロバイダとも連携可能です。 この高い柔軟性により、開発者は特定のベンダーや技術スタックに縛られることなく、プロジェクトの要件やチームの専門知識に応じて最適なAIモデルとエージェント構築フレームワークを選択できます。これは、将来的な技術の進化やビジネス要件の変化にも柔軟に対応できる、強力な利点となります。
-
ビジネスロジックへの集中と運用負荷の大幅な軽減: AgentCoreは、AIエージェントの実行環境(ランタイム)、スケーリング、メモリ管理、セキュリティ、ツール連携といったインフラ層の複雑な課題をフルマネージドサービスとして抽象化します。 これにより、開発チームは、インフラのプロビジョニングや維持管理といった「差別化されない重い作業」から解放され、エージェントのコアとなるビジネスロジック(推論、タスク実行、データ分析アルゴリズム)の設計と実装に完全に集中できます。結果として、プロトタイプから本番環境への移行期間が劇的に短縮され、市場投入までの時間を加速することが可能です。
-
RAGとCode Interpreterの統合による高度なデータ分析能力: Amazon Bedrock Knowledge BasesとAgentCore Code Interpreterの組み合わせは、AIエージェントに革新的なデータ分析能力をもたらします。Knowledge BasesによるRetrieval Augmented Generation (RAG) は、営業プレイブックや製品カタログのような非構造化データから、自然言語クエリに基づいて関連コンテキストを効率的に抽出し、エージェントの推論を強化します。 さらに、Code Interpreterは、取得した情報や構造化データに対してPythonなどのコードをセキュアなサンドボックス環境で実行し、複雑な統計分析、データ変換、カスタムレポートやグラフの生成といった高度な処理を可能にします。 この統合されたアプローチにより、エージェントは単なる情報検索にとどまらず、多岐にわたるデータソースから深いビジネスインサイトを自律的に導き出し、実用的なBIソリューションを実現できるでしょう。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。