「Stochastic KVルーティング」による適応的深層キャッシュ共有の実現
KVキャッシュの課題と深層方向の最適化
大規模言語モデル(LLM)の効率的な推論において、Key-Value(KV)キャッシュは反復的な計算を避けるために不可欠な要素ですが、そのメモリフットプリントは非常に大きく、推論コストに甚大な影響を与えています。KVキャッシュのメモリ使用量は、バッチサイズ、シーケンス長、そしてモデルの深さに線形に比例して増加し、特に長い入力や出力を持つ実用的なシナリオでは、パラメータ自体のメモリを上回ることが少なくありません。この膨大なメモリ消費は、GPUメモリに大きな負荷をかけ、最大バッチサイズやコンテキスト長の制約につながり、さらに大規模なテンソルのロードに伴うメモリ帯域幅のオーバーヘッドにより、顕著なレイテンシを引き起こします。
従来のKVキャッシュ削減に関する研究は、主に時間軸に沿った圧縮やエビクション(淘汰)に焦点を当ててきました。しかし、Appleの研究者たちは、深さ(層)方向が、直交的かつ堅牢な最適化の道筋を提供すると提唱しています。 既存の研究では、全てのレイヤーに対して完全なキャッシュが冗長である可能性が示唆されていましたが、レイヤー間でのキャッシュ共有を実装することは、スループットの低下や初回トークン生成時間(TTFT)の増加といった実用的な課題に直面していました。本研究は、レイヤーのキャッシュをドロップすることが情報損失なしに効率的な最適化を提供することを実証し、これらの課題への新たなアプローチを提案しています。
確率的KVルーティング(R-CLA)のメカニズム
この論文で提案されている核心的なアプローチは、「Random Cross-Layer Attention(R-CLA)」、すなわち確率的交差レイヤーアテンションと呼ばれる単純な学習スキームです。R-CLAは、モデルが深さ方向の多様なキャッシュ共有戦略に対してロバスト(堅牢)になるように適応させることを目的としています。
R-CLAの具体的なメカニズムは以下の通りです。訓練中(事前学習またはファインチューニングのフェーズ)、各レイヤーは、確率的に自身のKVステートにアテンションするか、あるいは先行するレイヤーのKVステートにアテンションするかを選択します。 例えば、レイヤーlが順伝播を実行する際、確率pで自身のKVステート(l' = l)を用いて標準的な自己アテンションを実行します。一方、確率1 - pで、ランダムに選択された先行レイヤーl'(l' < l)のKVステートにアテンションすることを強制されます。 この確率的なプロセスにより、モデルは特定のレイヤーと自身のKVステートとの厳格な依存関係から解放され、展開時に未知のハードウェア制約に対する柔軟性を確保できるよう適応します。
R-CLAがもたらす性能と展開の柔軟性
Stochastic KV Routing、特にR-CLAは、トランスフォーマーモデルの推論において、顕著なメモリ削減と性能の維持・向上、そして展開の柔軟性をもたらします。評価の結果、このスキームを事前学習またはファインチューニング中に適用することで、様々なモデルファミリーにおいて深さ方向のキャッシュ共有が可能になることが示されています。
具体的には、R-CLAはメモリ使用量を大幅に削減できます。例えば、レイヤーの50%から75%のキャッシュをドロップしても、同等の自己アテンションモデルを上回る性能を発揮することが示されています。 さらに、データが制約された環境下にある大規模モデルの場合、訓練中に導入されるランダム性が正則化効果として作用し、標準的なフルキャッシュベースラインと比較して、多くのタスクで性能が維持されるか、あるいは向上するという興味深い結果が報告されています。
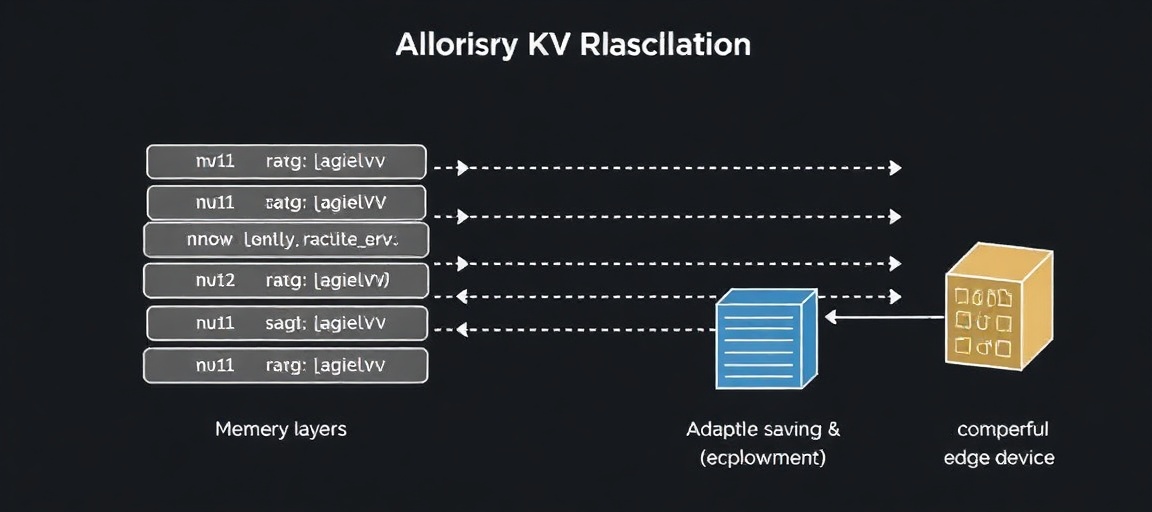
このアプローチの最大の利点の一つは、展開の柔軟性です。モデルが訓練時に多様な再利用パターンに適応しているため、テスト時に異なるキャッシュ共有戦略を選択しても、モデルはそれに対応できます。 これにより、高性能なクラスターでキャッシュの100%を保持する環境から、キャッシュのごく一部しか保持できないエッジデバイスまで、多様なハードウェア環境に対して、個別のモデルを訓練することなく単一のモデルを展開することが可能になります。 これは、ユーザーエクスペリエンスの品質(レイテンシ、スループット)と提供コストとの間のデリケートなトレードオフを乗り越える上で極めて重要な要素となります。
開発者・エンジニア視点での考察
-
ランダム交差レイヤーアテンション(R-CLA)を事前学習またはファインチューニング中に導入することで、特定のハードウェアに最適化されたモデルを複数用意することなく、単一モデルで多様な推論環境(高性能GPUクラスターからエッジデバイスまで)に対応できる汎用性の高いモデルを構築可能です。これは、モデルデプロイメント戦略を大幅に簡素化し、運用コストを削減します。
-
KVキャッシュの深層方向の共有は、GPUメモリ消費を劇的に削減する可能性があります(50〜75%削減の例も示唆されています)。特に長文コンテキストや大規模バッチサイズを扱う場合、この手法はメモリ帯域幅のボトルネックを緩和し、より高いスループットと短い初回トークン生成時間(TTFT)を実現するための鍵となるでしょう。
-
R-CLAによる訓練中のランダム性は、データが制約された設定での大規模モデルにおいて正則化効果として機能し、推論性能の維持または向上に寄与する可能性がある ため、モデルの汎化能力を向上させるための新たな訓練戦略として検討する価値があります。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。