NVIDIA Dynamoによるエージェント推論向けフルスタック最適化の深層
NVIDIA Dynamoが解決するエージェント推論の課題と全体アーキテクチャ
エージェント型AIワークロードは、システムプロンプトの再利用、推論トークンの一過性、ツール呼び出しによる推論の中断など、複雑な振る舞いを特徴とし、従来のLLM推論システムにとって大きな課題を提起します。特に、システムプロンプトと会話プレフィックスは頻繁に再利用される「ライトワンス・リードメニー(WORM)」アクセスパターンを示す一方で、推論中に生成される一時的なトークンは再利用されません。デフォルトのLRU(Least Recently Used)キャッシュ追い出し戦略では、これらの異なる再利用価値を持つKV(Key-Value)ブロックを区別できず、非効率なキャッシュ利用や高コストな再計算が発生していました。
NVIDIA Dynamoは、これらの課題を解決するために、オーケストレーターとして機能するオープンソースの分散推論フレームワークであり、推論エンジン自体ではなく、その周辺システムを最適化することに焦点を当てています。SGLang、NVIDIA TensorRT-LLM、vLLMなどの主要なオープンソース推論エンジンをサポートし、エンジンに依存しないアーキテクチャを提供します。Dynamoは、大規模な分散環境で生成AIおよび推論モデルを効率的に提供するために設計されており、その中核には「分離型サービング(Disaggregated Serving)」、スマートルーティング、階層型KVキャッシュ管理が含まれます。
フルスタック最適化の深掘り:KVキャッシュ管理とルーティング戦略
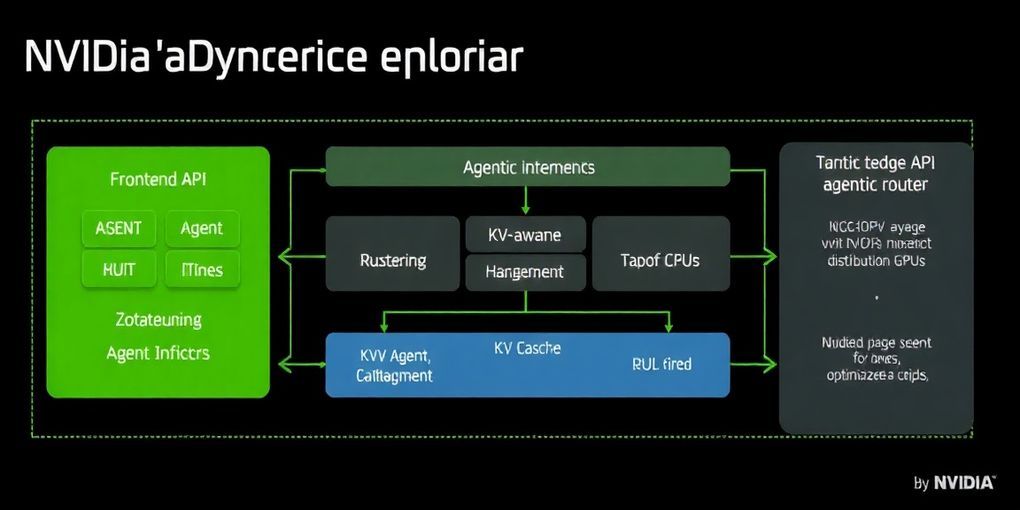
NVIDIA Dynamoは、エージェント推論の性能を向上させるために、フロントエンドAPI、ルーター、KVキャッシュ管理の3つのレイヤーでフルスタックの最適化を実施します。
-
フロントエンドAPIとAgent Hints: DynamoのフロントエンドAPIは、エージェントが推論リクエストに
priority(優先度)、osl(出力シーケンス長)、speculative_prefill(投機的プリフィル)といった「Agent Hints」と呼ばれるメタデータを付加することを可能にします。priorityはDynamo APIレベルでの重要度を制御し、ルーターのキュー順序やバックエンドのエンジン優先度に変換されます。oslは、ワーカーが占有される時間を推定するためにルーターによって使用され、ロードバランシングの精度を向上させます。speculative_prefillは、完全なリクエストが準備される前に、オーケストレーターにリクエストのプレフィックスを推定されるワーカー上にキャッシュし始めるよう信号を送ります。 -
KV-Aware Router: Dynamoのルーターは、これらのAgent Hintsをインテリジェントに利用します。
priorityとlatencyのヒントに基づいてキューの順序を制御し、ユーザーが直面する対話型ターンをバックグラウンドタスクよりも優先して実行します。また、oslを用いてGPUの占有時間を予測し、より正確なロードバランシングを実現します。ルーターは、ワーカーのキューの深さと各ワーカーのKVキャッシュ情報を評価し、これらの要素の重み付き組み合わせを用いて確率的なルーティング決定を行います。これにより、KVキャッシュの再計算を避けるリクエストルーティングが可能となり、大規模なMixture-of-Expert (MoE) モデルなど複雑なAIモデルのパフォーマンスと効率性が向上します. -
KVキャッシュ管理: エージェントワークロードは、システムプロンプトのように頻繁に再利用されるブロックと、推論トークンのように一度しか使用されないブロックを生成しますが、従来のLRU戦略ではこれらを区別できませんでした。Dynamoは、KVキャッシュブロックマネージャー(KVBM)を核として、GPU HBM、システムRAM、永続ストレージを含む洗練された多層キャッシュシステムを導入します。KVブロックはGPUからCPU、そしてディスクへと自動的に書き込みスルーパスを辿り、グローバルレジストリでシーケンスハッシュによって重複排除されます。一度登録されたブロックは不変であり、ストレージ層にアクセスできる任意のワーカーからアドレス指定可能となり、これによりサブエージェントのコールドスタート問題が直接解決されます。実験的なキャッシュピンニングもサポートされています。
これらの最適化により、Dynamo 1.0はNVIDIA Blackwellプラットフォームと組み合わせることで、推論パフォーマンスを最大7倍向上させることが示されています。
画期的な「分離型サービング」によるスループット最大化
NVIDIA Dynamoの最も特徴的な機能の一つが「分離型サービング(Disaggregated Serving)」です。これは、LLM推論における「プリフィル(プロンプト処理)」フェーズと「デコード(トークン生成)」フェーズを異なるGPUグループまたはノードに分離して実行するメカニズムです。
従来のLLMシステムでは、これらのフェーズを同じGPU上で共存させていたため、リソースの競合やアンバランスが生じていました。プリフィルフェーズは高い計算並列度(Tensor Parallelism)を必要とし、デコードフェーズはメモリ帯域幅に依存する特性があります。Dynamoは、これらのフェーズを分離することで、それぞれを独立して最適化し、GPUごとの割り当てと最適化を独立して行えるようにします。例えば、プリフィルGPUには高い計算並列度を適用し、デコードGPUにはメモリ帯域幅最適化を施すことで、両フェーズが効率的に計算され、スケーラビリティとパフォーマンスが向上します。
このアプローチは、GPUあたりのリクエスト処理数を増加させ、リソース使用率の向上と推論コストの削減に繋がります。Dynamoは、スケジューリング、KVキャッシュのオフロードとオンボーディングのためのメモリ管理、ノード間およびメモリ階層間でKVキャッシュを移動させるための低遅延データ転送(NIXL: NVIDIA Inference Transfer Library)を通じて、分離型サービングを実現しています。
エージェントAIシステム開発者・エンジニア視点での考察
-
エージェントの振る舞いを考慮したKVキャッシュライフサイクルの設計: DynamoのKVキャッシュ管理は、エージェント型ワークロード特有のKVブロック再利用パターンを考慮しています。開発者は、エージェントの設計段階で、どの情報が頻繁に再利用され、どれが一時的であるかを分析し、Dynamoのキャッシュピンニングや多層キャッシュ機能と連携させることで、キャッシュヒット率を最大化し、高コストな再計算を削減できるでしょう。特に、長期的な記憶やツールの状態をKVキャッシュに効率的にマッピングする戦略は、エージェントのパフォーマンスとコスト効率に直結します。
-
分散環境における効率的なリソースオーケストレーションの設計:
Agent Hints(priority、osl、speculative_prefill)の導入は、エージェントフレームワーク側が推論システムに対してより詳細な意図を伝える新しいパラダイムを提供します。これにより、従来のブラックボックス的な推論API利用から一歩進んで、推論のスケジューリングとリソース割り当てに積極的に介入できるようになります。複数のエージェントやサブエージェントが協調して動作する複雑なシステムでは、このヒントを動的に調整することで、全体のスループットとレイテンシのバランスを最適化する高度なオーケストレーション層を構築する可能性が生まれます。 -
異種GPU構成におけるDynamoのポテンシャル: 分離型サービングは、プリフィルとデコードのフェーズで異なるGPUリソース要件があることを示唆しています。これは、将来的に異なる世代や性能を持つGPUが混在する環境、あるいはエッジとクラウドの連携において、より柔軟かつコスト効率の良いリソース割り当てを可能にする基盤となり得ます。例えば、プリフィルに特化した高性能なGPUを、デコードには電力効率の良いGPUを割り当てるなど、ハードウェア選択の幅を広げ、AIインフラストラクチャ全体の最適化を促進する可能性があります。


