マルチモーダル評価器:Strands Evalsにおける画像からテキストへのタスクのためのMLLM-as-a-judge
MLLM-as-a-judgeの概要と従来の課題解決
画像からテキストへの生成AIタスクにおいて、モデルの出力が画像の内容を忠実に記述しているか、事実と合致しているかといった評価は、従来のテキストベースの評価指標では困難でした。BLEUやROUGEといった指標は、厳密な単語の一致や構文の類似性には優れるものの、意味的なニュアンス、事実の正確性、そして主観的な品質を捉えるのが苦手です。例えば、画像キャプション、ビジュアルQ&A (VQA)、チャート分析、文書理解といったユースケースでは、生成されたテキストがソース画像に根ざしているかを検証することが不可欠です。しかし、テキストのみの評価器では、キャプションが画像を忠実に記述しているか、抽出された情報が文書と一致しているか、画面の要約がページに存在しないボタンを幻覚していないかなどを判断できません。ガートナーは、2030年までに企業ソフトウェアの80%がマルチモーダルになると予測しており、自動化されたマルチモーダル評価の必要性が高まっています。従来の評価手法が抱えるこれらの課題に対し、「MLLM-as-a-judge」は、マルチモーダル大規模言語モデル(MLLM)を評価器として活用することで、人間のような質的評価を大規模に実現するアプローチを提供します。これにより、高コストな人間によるレビューと信頼性の低いテキストのみの代理評価との間のギャップを埋めることが可能になります。
Strands EvalsにおけるMLLM評価器の実装と技術的詳細
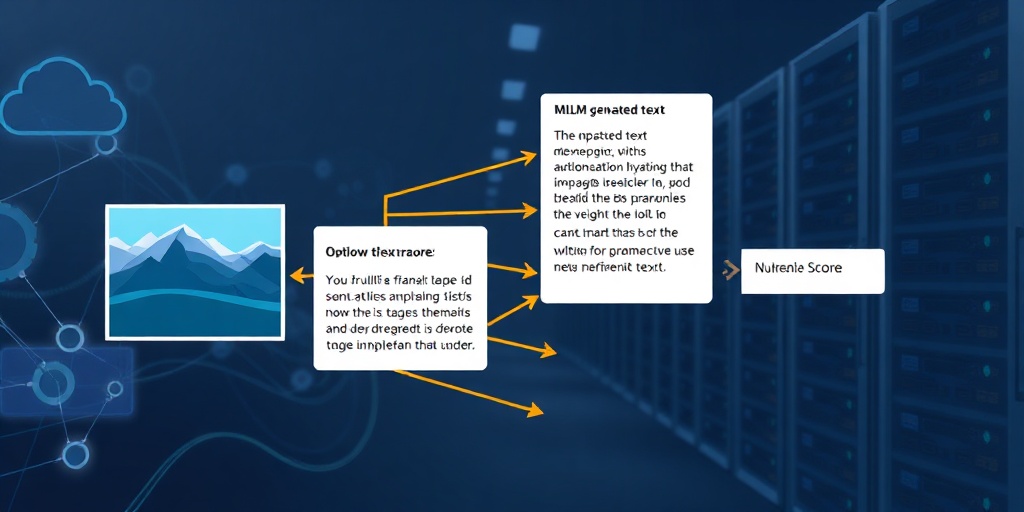
AWSは、Strands Evals SDKにおいて、画像からテキストへのタスク向けに4つの新しいMLLM-as-a-judge評価器を発表しました。これらは「全体的な品質 (Overall Quality)」、「正確性 (Correctness)」、「忠実度 (Faithfulness)」、「指示の遵守 (Instruction Following)」を評価します。各評価器は、画像とテキストの出力をソース画像と照合してスコアを付けます。評価のワークフローでは、MLLM評価器は画像、クエリ、モデルの応答、そしてオプションとして参照応答を受け取ります。その後、画像に基づいて根拠のあるスコアと、デバッグに利用できる推論文字列を返します。これにより、モデルが生成したテキストが、事実の誤り、創造された詳細、または無視された指示といった失敗モードを特定し、それぞれ異なる修正を必要とするため、単一のスコアに集約するよりもデバッグを容易にします。
Strands EvalsのMultimodalOutputEvaluatorは、MLLMをジャッジとして利用し、ユーザー定義のルーブリックに基づいて応答を評価します。この評価器は、入力にメディアが含まれる場合にはStrands SDKのコンテンツブロックを出力し、それ以外の場合はプレーンテキストのプロンプトにフォールバックします。これにより、MLLM評価器は、VQA、チャート/文書QA、画像キャプション、OCRスタイルのタスクなど、画像や文書が関わるエージェント出力の品質評価に適用できます。開発者は、Amazon Bedrock上のジャッジモデルを選択し、精度、コスト、レイテンシーのバランスを考慮できます。また、プロンプト設計の選択肢を適用することで、ジャッジの評価と人間の評価との整合性を向上させることが可能です。
評価の質向上と開発ワークフローへの影響
MLLM-as-a-judge評価器の導入は、生成AIモデルの開発サイクルにおいて、評価の質と効率性を大きく向上させます。従来の評価指標では捉えきれなかった、モデル出力の微妙なニュアンスやコンテキスト依存の正確性を、人間により近い形で評価できるようになります。これにより、開発者はモデルのパフォーマンスをより深く理解し、具体的な改善点に焦点を当てた調整を行うことが可能になります。
また、MLLM評価器は自動化された評価を大規模に実行できるため、高コストで時間のかかる手動レビューの必要性を大幅に削減します。継続的インテグレーション(CI)パイプラインに組み込むことで、視覚的な幻覚、事実の誤り、指示違反などを自動的に検出し、本番環境にデプロイされる前に問題を捕捉できます。これにより、開発者はより迅速なフィードバックループを実現し、モデルの反復的な改善を加速できます。Strands Evalsは、ケース(テストシナリオ)、実験(ケースのバンドル)、評価器(LLM-as-a-judge)という3つのコアコンセプトを中心に構成されており、MLLM評価器は既存の「ケース→実験→レポート」ワークフローに簡単に組み込むことができます。
開発者・エンジニア視点での考察
-
定量的指標から質的評価へのシフトによる迅速な反復開発: 従来のBLEUやROUGEのような定量的指標に加えて、MLLM-as-a-judgeは、生成されたテキストが画像に忠実であるか、指示に適切に従っているかといった、より人間中心の質的フィードバックを提供します。これにより、開発者はモデルの出力の「なぜ」良いのか、悪いのかをより深く理解し、よりターゲットを絞ったモデルのチューニングやプロンプトエンジニアリングを迅速に行えるようになります。
-
ドメイン固有の評価基準の柔軟な組み込み: Strands EvalsのMLLM評価器は、カスタムルーブリックの定義をサポートしています。これにより、特定の業界やアプリケーション固有の評価基準(例:医療画像のレポート生成における特定の専門用語の正確性、製品カタログ記述におけるブランドガイドラインの遵守など)をMLLMの判断基準として組み込むことが可能になります。これにより、汎用MLLMだけでは難しい、ニッチなドメインでの高精度な評価システムを構築できます。
-
継続的デプロイメント(CD)パイプラインにおける品質ゲートとしての活用: MLLM評価器をCI/CDパイプラインに統合することで、生成AIモデルのデプロイ前に、幻覚や事実誤認などの致命的な品質問題を自動的に検出する品質ゲートとして機能させることができます。これにより、本番環境でのリスクを軽減し、デプロイの信頼性を高めるだけでなく、開発者が安心して新しいモデルバージョンをリリースできる環境が構築されます。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。