Stream Vision AgentsとAmazon Nova 2 Sonicで実現するリアルタイム音声エージェント:先進アーキテクチャと開発の考察
リアルタイム音声エージェントの課題とStream Vision Agentsの役割
生産レベルの自然で応答性の高い音声エージェントの構築は、複雑なエンジニアリング課題を伴います。スピーチ・ツー・スピーチモデルのオーケストレーション、低レイテンシのオーディオストリーミング管理、接続ライフサイクルの処理に加え、Web、モバイル、デスクトップアプリケーション全体で一貫したエクスペリエンスを提供する必要があります。従来の音声AIアプリケーションでは、音声認識、言語モデル、テキスト・ツー・スピーチサービスをリアルタイムで統合し、数百ミリ秒以内に処理を完了させなければならず、遅延は会話フローを損ないユーザーに不満を与えていました。また、不安定なネットワーク接続、ブラウザの互換性、セッションタイムアウトといった実世界のデプロイにおける課題にも対処する必要があります。
Stream Vision Agentsは、これらの課題に対処するために設計されたオープンソースのフレームワークです。WebRTCを介したリアルタイムのビデオおよびオーディオ入力に対応し、500ミリ秒未満の参加時間と0ミリ秒のオーディオ/ビデオレイテンシを実現する超低レイテンシを提供します。 このフレームワークは、ビデオ、オーディオ、テキスト、LLM推論、フレームごとの機械学習モデルといった真のマルチモーダリティを処理でき、高い拡張性を持ちます。YOLOやRoboflowのような任意の物体検出モデル、および主要なLLM(OpenAI、Gemini、Claude、xAI、AWS Novaなど)をプラグイン可能です。 Stream Vision Agentsは、動画配信と検出ロジックを分離することで、従来のシステムで発生しがちなパイプラインの停滞を防ぎ、リアルタイムなユーザー体験を保証するアーキテクチャを採用しています。 また、音声活動検出(VAD)や話者分離によるスマートなターン検出、ツール呼び出し、Stream Chatを介した組み込みメモリ、Twilioとの電話統合などの機能も提供し、本番環境での利用を想定した設計となっています。
Amazon Nova 2 Sonic:統合型スピーチ・ツー・スピーチモデルの深層
Amazon Nova 2 Sonicは、エンタープライズユースケース向けに設計された独自のマルチモーダル基盤モデル(FM)であり、Amazon Bedrockを通じて提供されます。 このモデルの最も重要な特徴は、音声理解と音声生成能力を単一のモデルに統合している点です。これにより、従来の音声エージェントパイプラインで一般的だった、音声認識(ASR)→言語モデル(LLM)→テキスト・ツー・スピーチ(TTS)の個別のモジュールを連結するアーキテクチャとは一線を画し、人間のような音声会話を低レイテンシで実現します。
Nova 2 Sonicは、リアルタイムのスピーチ・ツー・スピーチ会話に不可欠な低レイテンシを核としています。 また、多言語対応が強化され、元の英語、フランス語、イタリア語、ドイツ語、スペイン語に加え、ポルトガル語とヒンディー語をサポートします。さらに、「ポリグロットボイス」を導入し、単一の音声が会話中に複数の言語を流暢に切り替える「コードスイッチング」能力を提供します。 モデルは18種類の表現豊かな声で音声を生成でき、幅広い話し方に対応した多言語での音声理解を可能にします。 1Mトークンという大規模なコンテキストウィンドウを備えており、長時間の会話でも文脈を失うことなく対応できます。 加えて、ツール使用や関数呼び出しにネイティブで対応しており、非同期的なツール呼び出しもサポートするため、エージェントは会話を中断することなくバックグラウンドでタスクを実行できます。 Amazon Bedrockとの統合により、GDPRやHIPAAなどの一般的なデータセキュリティおよびコンプライアンス基準をサポートするエンタープライズレベルのセキュリティが提供されます。
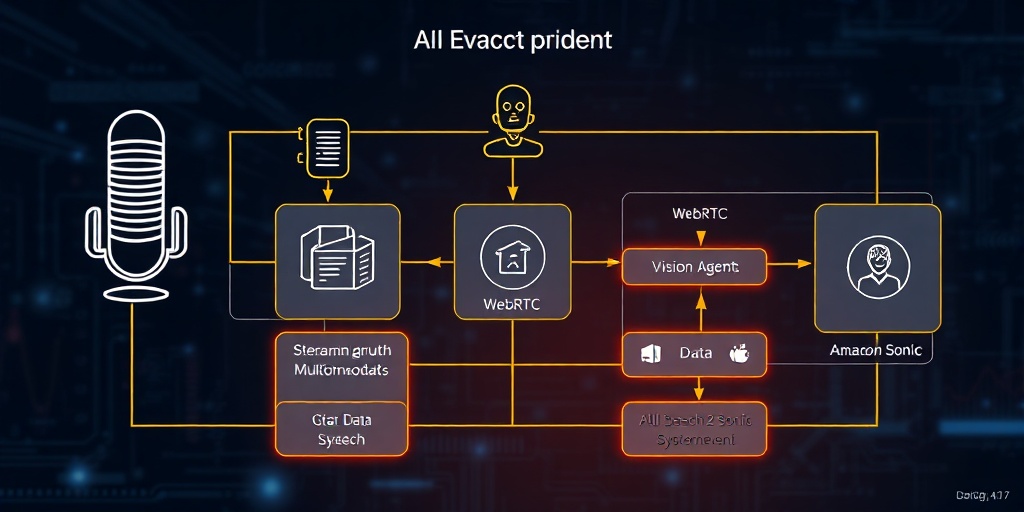
Stream Vision AgentsとAmazon Nova 2 Sonicの連携アーキテクチャ
Stream Vision AgentsとAmazon Nova 2 Sonicの連携は、リアルタイム音声エージェントの構築を劇的に簡素化し、パフォーマンスを向上させます。Stream Vision Agentsは、リアルタイムのメディアストリーミング(WebRTC)と多様なAIコンポーネントのオーケストレーションを担うオープンソースフレームワークとして機能します。 一方、Amazon Nova 2 Sonicは、音声理解から推論、音声生成までを一貫して処理する統合型のスピーチ・ツー・スピーチAIエンジンとして中心的な役割を果たします。
この連携アーキテクチャでは、ユーザーの音声入力はWebRTCを介してStream Vision Agentsにリアルタイムでストリーミングされます。Stream Vision Agentsは、このオーディオデータをAmazon Nova 2 Sonicに効率的にルーティングします。Vision AgentsのAWS Bedrockプラグインは、Amazon Nova 2 Sonicが持つ8分間の接続制限を透過的に処理する機能を提供します。具体的には、5分間の沈黙(設定可能)の後、沈黙中に再接続を試み、7分後には音声活動に関わらず強制的に再接続を実行することで、中断のない会話を保証します。 この自動セッション管理機能は、開発者が低レベルのネットワーク接続管理から解放される大きな利点です。Nova 2 Sonicは、受け取った音声データに対して、その統合されたモデル内でリアルタイムに音声認識、意味理解、推論、そして応答音声の生成を行います。このプロセスは、従来のASR-LLM-TTSの連鎖に比べて、はるかに低いレイテンシで実行されます。生成された音声応答は、再びStream Vision Agentsを通じてユーザーにリアルタイムで届けられます。このシームレスな双方向ストリーミングは、署名付きURLを用いた直接WebSocket接続によって実現され、セキュアで低レイテンシな通信経路を確立します。
リアルタイムAIエージェント開発におけるパフォーマンスとスケーラビリティ
リアルタイムAIエージェントの成功は、そのパフォーマンスとスケーラビリティに大きく依存します。Stream Vision AgentsとAmazon Nova 2 Sonicの組み合わせは、これらの側面において卓越した能力を発揮します。Stream Vision Agentsは、StreamのグローバルエッジネットワークとWebRTCを基盤とすることで、オーディオ/ビデオのレイテンシを0ミリ秒、参加時間を500ミリ秒未満に抑える超低レイテンシを実現します。 これは、ドローンによる火災検知、ゴルフスイングコーチング、理学療法修正など、わずかな遅延も許されないユースケースに十分な速度です。
Amazon Nova 2 Sonicは、統一されたスピーチ・ツー・スピーチアーキテクチャにより、音声理解と生成をリアルタイムで実行し、業界をリードする低レイテンシと価格性能を提供します。 特に、WebRTCは不安定なネットワーク状況下でビットレートを動的に調整することで、接続切断を減らしつつ音声品質を維持する役割を担います。 両サービスはAWSによって完全に管理されており、高い回復性を持ちながら自動的にスケーリングされるため、開発者はインフラストラクチャの複雑さから解放されます。 Stream Vision Agentsは、Kubernetes Readyであり、HTTPサーバー、Prometheusメトリクスエンドポイント、ステートレスなエージェント設計により、水平方向のスケーリングとゼロダウンタイムデプロイメントをサポートします。 さらに、Nova 2 Sonicは、異なるアクセントやバックグラウンドノイズに対しても高い堅牢性を持ち、実世界のデプロイメントシナリオにおける信頼性を向上させています。 このような堅牢性とスケーラビリティは、コールセンターの自動化、教育、言語学習、旅行、通信、エンターテイメントなど、幅広い業界での会話型AIエージェントのユースケースを可能にします。
開発者・エンジニア視点での考察
-
モジュール化されたAIコンポーネントの活用とエコシステムの選択: Stream Vision Agentsのプラグイン可能なアーキテクチャは、開発者が特定の機能(ASR、LLM、TTS、CV)に対してベンダーロックインを避けつつ、Amazon Nova 2 Sonicを含む最適なAIモデルを選択・統合できる柔軟性を提供します。これは、長期的なプロジェクトのスケーラビリティと技術的負債の軽減に寄与し、特定のプロバイダーの進化に依存しすぎることなく、最新かつ最適な技術スタックを柔軟に採用できる戦略的なメリットをもたらします。
-
WebRTCとエッジコンピューティングによる低レイテンシ設計の最適化: リアルタイム音声エージェント開発において、Stream Vision Agentsが提供するWebRTCベースの超低レイテンシインフラとエッジネットワークは極めて重要です。これにより、従来のサーバーサイド処理に起因する遅延を最小限に抑え、人間とAI間の自然な会話フローを実現するためのアーキテクチャ設計が可能になります。特に、ネットワーク状況に応じたビットレート調整や、Amazon Nova 2 Sonicの接続制限に対する自動セッション管理は、開発者が低レベルのネットワーク課題から解放され、より高レベルのエージェントロジック開発に集中できる大きなメリットです。
-
統合型スピーチ・ツー・スピーチモデルの採用による開発の簡素化と効率化: Amazon Nova 2 Sonicのようなスピーチ認識・推論・音声生成を単一モデルで統合するアプローチは、従来のASR→LLM→TTSの多段階パイプラインと比較して、開発工数とシステム複雑性を大幅に削減します。開発者は各コンポーネント間の連携ロジックやレイテンシ管理に煩わされることなく、エージェントの対話ロジックと機能呼び出し(ツール使用)に集中できます。これにより、迅速なプロトタイピングと本番環境への展開が加速され、特にリアルタイム性と自然な対話が求められるユースケースにおいて、開発効率とユーザー体験の両面で優位性を確立できます。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。


