AWSにおける基盤モデル学習と推論のための構成要素:技術的深掘り
大規模基盤モデル学習のための高性能インフラストラクチャ
現代の生成AIモデル、特に基盤モデル(Foundation Models: FMs)の事前学習には、前例のない計算規模が要求されます。数千のアクセラレータが数日から数ヶ月間連続稼働する分散学習クラスターが必要とされ、PyTorchのようなフレームワークを用いて数百のアクセラレータ(AWS Trainium、AWS Inferentiaチップ、NVIDIA GPUなど)間でワークロードを並列化することが不可欠です。
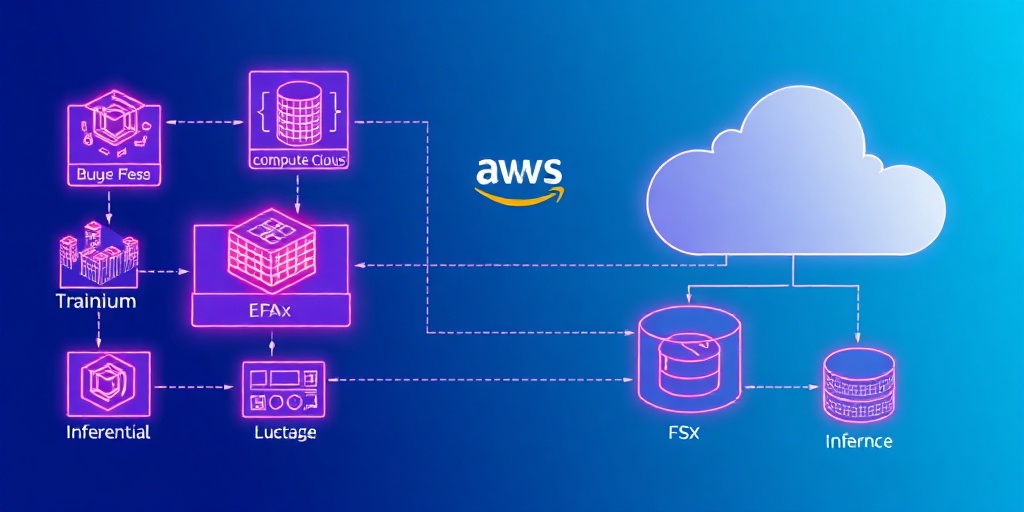
Amazon SageMaker HyperPodは、このような複雑なワークロードを管理するための重要な要素です。これは、耐障害性のある分散学習クラスターのオーケストレーションを簡素化し、数千のアクセラレータにわたるトレーニングワークロードの自動分割を可能にするSageMaker分散学習ライブラリを内蔵しています。このライブラリはAWSインフラストラクチャ向けに最適化されており、パイプライン並列性、テンソル並列性、および完全にシャーディングされたデータ並列性をサポートします。特に、SageMaker All Gather (AG) collectivesは、NCCLと比較して通信性能を10〜20%向上させることができます。これにより、大規模クラスターにおけるスケーリング効率が向上します。
また、基盤モデル学習におけるデータアクセス性能は極めて重要です。Amazon FSx for Lustreは、高性能な分散ファイルストレージサービスであり、サブミリ秒のレイテンシ、テビバイトあたり最大1GBpsのスループット、数百万IOPSを提供します。これは、機械学習やHPC(高性能計算)のような高速なストレージアクセスを必要とするアプリケーションに最適化されています。 さらに、Elastic Fabric Adapter (EFA) は、Amazon EC2アクセラレーテッドコンピューティングインスタンスと組み合わせて、高スループットかつ低レイテンシのノード間通信を可能にし、大規模な分散学習においてデータ転送のボトルネックを解消します。
基盤モデル推論の最適化と効率的なデプロイメント
基盤モデルの推論において、最適なパフォーマンスとコスト効率を達成することは、サービス提供の鍵となります。Amazon SageMakerの推論機能は、モデルのデプロイを簡素化し、あらゆるユースケースで最適な価格性能を実現します。SageMakerは、モデルのアーキテクチャを分析し、投機的デコーディングやカーネルチューニングなどの最適化を適用し、NVIDIA AIPerfを使用して実際のGPUインフラストラクチャでベンチマークを実行することで、最適な推論構成を推奨します。これにより、モデルを本番環境にデプロイするまでの期間を数週間から数時間に短縮できます。
SageMakerは100種類以上のインスタンスタイプを提供しており、様々な計算およびメモリ要件に対応可能です。これにより、特定のモデルやワークロードに最適なリソースを選択できます。さらに、基盤モデルのような大規模モデルの推論性能を向上させるため、特殊なディープラーニングコンテナ(DLCs)、ライブラリ、ツールが提供されています。これには、モデル並列性や大規模モデル推論(LMI)をサポートする機能が含まれます。
コスト削減とアクセラレータの利用効率向上には、単一インスタンスに複数のモデルをデプロイするマルチモデルエンドポイントも有効です。 インフラストラクチャ管理を完全に排除したい場合には、Amazon Bedrockを介したサーバーレス推論の利用も可能です。Bedrockの次世代推論エンジンは、コストとレイテンシを自動的に最適化し、GPUの管理なしにゼロオペレーターアクセスセキュリティを強制します。
開発ワークフローとMLOpsの強化
基盤モデルのライフサイクル全体を効率的に管理するためには、統合された開発環境と堅牢なMLOpsパイプラインが不可欠です。Amazon SageMaker Studioは、データサイエンティストや開発者がデータ準備、モデル構築、トレーニング、チューニング、評価、デプロイ、監視といった機械学習タスクを実行できる、統合されたウェブベースのインターフェースを提供します。 JupyterLab Notebooks、Code Editor(Code-OSSベース)、Visual Studio Code Open Source、RStudioなど、多様なIDEをサポートしており、開発者の好みに応じた柔軟な開発環境を実現します。
SageMaker HyperPodには、SageMaker DebuggerやTensorBoardとの連携など、モデルのパフォーマンスを向上させるための組み込みMLツールが含まれています。SageMaker Debuggerはリアルタイムのトレーニングメトリクスをキャプチャし、プロファイルを提供することで、モデルの収束問題やパフォーマンスボトルネックの特定を支援します。 これらのマネージドサービスは、インフラストラクチャのセットアップと運用に伴う複雑さを軽減し、開発者が基盤モデル自体のイノベーションに集中できる環境を提供します。
開発者・エンジニア視点での考察
-
分散学習の抽象化と最適化の活用: Amazon SageMaker HyperPodと分散学習ライブラリは、複雑なマルチノード・マルチGPU環境での大規模基盤モデル学習の課題(同期、データ転送ボトルネックなど)を大幅に抽象化し、AWSインフラストラクチャに最適化された形で提供します。開発者は、低レベルの通信プリミティブやクラスタ管理ではなく、モデルアーキテクチャやハイパーパラメータチューニングに集中でき、SageMaker All Gather (AG) collectivesのようなAWS独自の最適化により、オープンソースライブラリ(DeepSpeed、PyTorch FSDPなど)を使いながらも通信性能を最大限に引き出すことが可能です。
-
推論コストとパフォーマンスの継続的最適化: SageMaker Inferenceのレコメンデーション機能は、モデルのアーキテクチャに基づいて最適なインスタンスタイプ、構成、およびカーネルチューニングを自動で推奨するため、推論デプロイメントにおける試行錯誤のコストと時間を劇的に削減します。開発者は、推論スループットとレイテンシの目標値に応じて、マネージドサービスが提供する多様な最適化オプション(マルチモデルエンドポイント、専用DLCs、サーバーレスなAmazon Bedrockなど)を積極的に活用し、運用中のモデルのコスト効率とユーザー体験を継続的に改善する戦略を立てるべきです。
-
MLOpsを通じたイノベーションの加速と運用効率の向上: SageMaker Studioを中心とした統合開発環境と、HyperPod、Debugger、TensorBoardといったツール群の活用は、基盤モデルの開発からデプロイ、そして継続的な改善に至るMLOpsのサイクルを効率化します。これにより、インフラ管理の手間を最小限に抑えつつ、実験管理、モデルのデージング、監視、そしてバージョン管理といったMLOpsのベストプラクティスを容易に実践でき、開発チームはモデルの性能向上や新機能開発といった、より付加価値の高い活動にリソースを集中させることができます。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。