IBM Granite 4.1 LLM:基盤から紐解くその構築技術
Granite 4.1 LLMの基盤アーキテクチャ
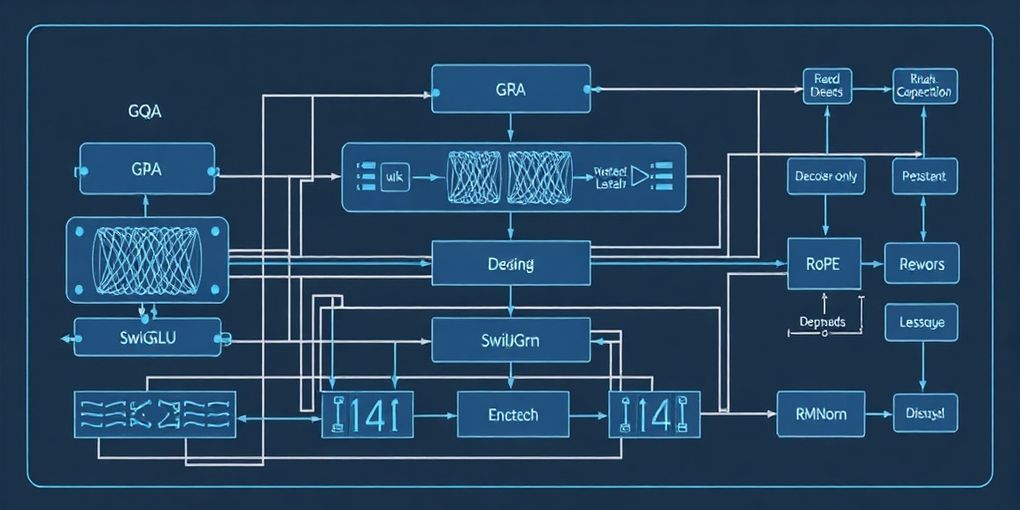
IBM Granite 4.1は、30億、80億、300億パラメータサイズの高密度デコーダーオンリー型大規模言語モデル(LLM)ファミリーとして発表されました。これらのモデルは、その効率性と性能を支える堅牢なTransformerベースのアーキテクチャを採用しています。核となる設計要素としては、Grouped Query Attention (GQA)、Rotary Position Embeddings (RoPE)、SwiGLUアクティベーション、RMSNorm、そして共有された入出力埋め込みが挙げられます。特にGQAの採用は、クエリヘッドをグループ化してキー・バリューヘッドを共有することで、推論時のメモリ消費を削減し、スループットを向上させることを目的としています。RoPEは、絶対位置情報に加えて相対位置情報をモデルに組み込むことで、特に長いシーケンスにおける位置情報の解釈能力を高めます。SwiGLUアクティベーション関数は、標準的なReLUやGeLUと比較して表現力を向上させ、モデルの学習能力を強化します。これらの技術的選択は、Granite 4.1が既存のGranite 4.0-H-Small (32B-A9B MoE)モデルと同等かそれ以上の性能を、よりシンプルな密なアーキテクチャと少ないパラメータ数で達成する要因となっています。
多段階学習パイプラインとデータキュレーション
Granite 4.1 LLMの構築において、IBM Researchチームはデータ量の拡大よりもデータ品質の厳格なキュレーションを重視しました。約15兆トークンに及ぶデータセットは、5段階にわたる多段階の事前学習パイプラインを通じて処理されています。最初の2段階で広範な事前学習を行い、続く3段階目と4段階目では高品質データの段階的なアニーリング(徐々に高品質なデータにシフト)を実施しました。最終の5段階目では、最大512Kトークンという長文コンテキスト拡張に焦点を当てた学習が行われ、これによりモデルは短いコンテキストタスクの性能を損なうことなく、非常に長い文書を処理できるようになっています。
さらに、モデルの性能を向上させるために、約410万件の高品質なキュレーション済みサンプルを用いた教師ありファインチューニング(SFT)が実施されました。このSFTデータの選定には、「LLM-as-Judge」フレームワークが活用されており、自動的かつ効率的に高品質な指示応答ペアを生成・選別しています。 SFT後には、オンポリシーのGRPOとDAPOロスを用いた強化学習(RL)が適用され、数学、コーディング、指示理解、一般的なチャット能力において体系的な性能強化が図られました。このアプローチにより、Granite 4.1モデルはツールコーリング、指示理解、チャットなどの分野で顕著な性能向上を達成しています。
エンタープライズ向け性能最適化とエコシステム
Granite 4.1ファミリーは、エンタープライズ環境での利用を強く意識して設計されています。予測可能なレイテンシ、安定したトークン使用量、および低い運用コストを実現することで、効率性と信頼性が最優先される企業ワークロードに最適な選択肢となります。モデルはApache 2.0ライセンスの下で公開されており、研究利用と商用利用の両方で高い柔軟性を提供します。
また、Granite 4.1はテキストベースのLLMに留まらず、広範なエンタープライズAIワークフローをサポートする包括的なエコシステムの一部として展開されています。具体的には、文書理解、チャートや画像からの情報抽出に特化したGranite Vision 4.1、多言語音声認識および翻訳モデルであるGranite Speech 4.1、そしてAIシステムにおけるハーム検出(有害性検出)を担うGranite Guardian 4.1などが含まれます。Granite Speech 4.1には、非自己回帰型(NAR)モデルも含まれ、高いスループットとGPU利用率を実現し、エッジデバイスなどリソース制約のある環境でのリアルタイム処理に新たな可能性を提示しています。 これらのモデル群は、多言語対応(英語、ドイツ語、スペイン語、フランス語、日本語、ポルトガル語、アラビア語、チェコ語、イタリア語、韓国語、オランダ語、中国語)も強化されており、グローバルなエンタープライズ展開を強力に支援します。
開発者・エンジニア視点での考察
-
Apache 2.0ライセンスと多様なモデルサイズ(3B、8B、30B)により、Granite 4.1は小規模なエッジデバイス向けアプリケーションから、大規模なクラウドベースのエンタープライズソリューションまで、高い柔軟性を持って導入・カスタマイズが可能です。これは、特定のビジネス要件や利用可能なコンピューティングリソースに応じて最適なモデルを選択できる点で、開発者にとって大きなメリットとなります。
-
512Kトークンに及ぶ長文コンテキスト処理能力と、OpenAIの関数定義スキーマに準拠した強化されたツールコーリング機能は、複雑なエージェントベースシステムやRAG(検索拡張生成)アプリケーション開発において、プロンプトエンジニアリングの簡素化と性能向上に直結します。これにより、外部ツールやデータベースとの連携がよりシームレスになり、高度な自動化ワークフローの構築が容易になります。
-
Granite Speech 4.1の非自己回帰型(NAR)モデルの採用は、従来の自己回帰型モデルと比較してGPU利用率とスループットの大幅な向上を実現しています。これは、リアルタイム音声認識や翻訳を必要とするアプリケーション(例:コールセンターのライブトランスクリプション、会議の同時通訳、エッジデバイスでの音声コマンド処理など)において、低レイテンシかつ高効率なAIソリューション開発に新たな可能性をもたらします。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。


