Vanguardのバーチャルアナリストが示すAIレディデータ構築の道筋:複雑な金融データをAI活用可能な資産へ
AIレディデータ:Vanguardが直面した課題と基本原則
投資運用会社Vanguardは、金融アナリストが複雑なデータセットに迅速かつ直接的にアクセスできないという課題に直面していました。既存のワークフローでは、洗練されたSQLクエリの作成が必要であり、データチームからの応答には数日を要することが一般的でした。この問題はVanguardに固有のものではなく、会話型AIはアナリストに即座の応答を提供するスケーラブルなソリューションとして認識されていますが、その導入には適切な基盤モデルの選択以上に「AIレディなデータインフラストラクチャ」が不可欠であるという結論に至りました。
Vanguardは、この課題を機械学習の問題ではなくデータアーキテクチャの問題であると捉え直し、AI対応データのための8つの指導原則を策定しました。これらの原則は、既存のデータ基盤(データプラットフォーム、統合、相互運用性など)を強化し、AI対応データをサポートするために拡張するものです。 この取り組みには、データエンジニア、ビジネスアナリスト、コンプライアンス担当者、セキュリティチーム、およびビジネスステークホルダーを含む異職能間のコラボレーションが不可欠でした。各チームが専門知識を持ち寄り、明確な所有権モデル、セマンティック定義、品質基準を備えた運用モデルを確立しました。
AWSを活用したVirtual Analystのアーキテクチャと技術的実現
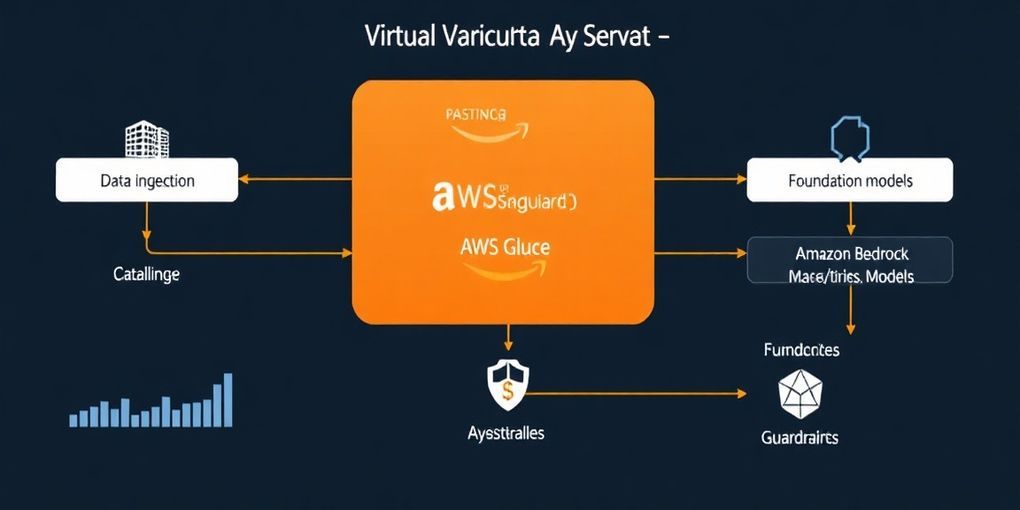
Vanguardの「Virtual Analyst」ソリューションは、AWSの統合された包括的なサービス群を活用して構築されました。このアーキテクチャは、AI対応データを構築するための豊富な機能セットを提供しています。
具体的なサービスとしては、自然言語理解を可能にする基盤モデル(Foundation Models)のためにAmazon Bedrockが使用されました。 また、Vanguardの機密性の高い金融データを保護するため、AIの入力と出力を保護する目的でAmazon Bedrock Guardrailsが導入されています。 高度な分析機能にはAmazon Redshiftが用いられ、データカタログの自動化にはAWS Glueが活用されています。
AIが正確でビジネスに関連性の高いインサイトを生成できるようにするためには、セマンティックコンテキストとメタデータ管理を可能にするデータインフラストラクチャが求められました。 Vanguardは、メタデータとセマンティックレイヤーの実装を通じて、AIが生成するSQLクエリの高い精度を実現しました。 このアプローチにより、最も洗練された基盤モデルであっても、信頼性の高い結果を提供するための適切なデータ基盤が確保されました。
データガバナンスとセキュリティ:金融業界におけるAI活用の要件
金融サービス業界では、AIシステムの導入において厳格なセキュリティとコンプライアンスの要件を満たすことが不可欠です。VanguardのVirtual Analystの構築においても、データガバナンスとセキュリティ対策が中核をなしました。
具体的には、エンタープライズのアイデンティティ管理、ロールベースのデータアクセス制御、クエリレベルの認証、および保持ポリシーを確立するために、コンプライアンスおよびセキュリティチームとの早期連携が重視されました。 Vanguardは、規制要件を満たしつつビジネスの俊敏性をサポートするために、認証イベントのログ記録を実装しました。 既存のデータアクセスポリシーを新しいAIシステムにマッピングし、必要に応じて行レベルおよび列レベルのセキュリティを実装することも重要です。
さらに、AIガバナンスは、AIユースケース、セマンティックレイヤー、およびAIツールにデータガバナンスの知識領域を適用し、コンプライアンスを確保することを目指しています。 これは、リスクチームと連携して監視フォーラムに参加し、監視プラクティスが遵守されていることを確認する活動を含みます。
計測可能な成果とデータ戦略の進化
AI対応データへの注力は、Vanguardに目覚ましい成果をもたらしました。Virtual Analystの導入により、複雑な金融クエリに対するインサイト取得までの時間が、従来の数日から数分に短縮されました。 これにより、SQLの知識がないビジネスユーザーでも独立してデータにアクセスできるようになり、データチームの定型的な分析リクエストに対する作業負荷が軽減されました。
この成功は、Vanguardのデータ戦略の進化を加速させました。同社は、ワークロードの分離と独立したスケーリングのためにAmazon Redshiftのマルチウェアハウスアーキテクチャを導入し、最終的にはデータメッシュアプローチへの移行を探求しています。 この進化は、Vanguardが組織的に規模を拡大しながら、技術的な基盤と運用上の卓越性を構築する能力をサポートします。 Virtual Analystは、金融サービスのAI活用におけるデータ基盤の重要性を示す具体的な成功事例であり、その成果は複数のVanguardビジネスユニット全体で再利用可能なフレームワークとして確立されつつあります。
開発者・エンジニア視点での考察
-
データ基盤の戦略的優先順位付け: 大規模な言語モデル(LLM)のような高度なAIモデルの選定と導入は重要ですが、エンタープライズ環境におけるAIシステムの信頼性と精度は、その基盤となるデータの品質とアクセス性に大きく依存します。Vanguardの事例が示すように、AIモデル自体よりも「AIレディデータ」の構築、すなわちデータ取得、クレンジング、カタログ化、セマンティックな富化に焦点を当てた投資こそが、AIプロジェクト成功の真のボトルネックを解消します。開発者は、最新のモデルを追いかけるだけでなく、基盤となるデータパイプラインとデータプロダクトの堅牢性を確保することに優先的にリソースを配分すべきです。
-
メタデータとセマンティックレイヤーの構築: AIによる自動化されたクエリ生成や洞察抽出の精度を最大化するためには、単なるデータの保存や集約を超えた、リッチなメタデータとセマンティックレイヤーの構築が不可欠です。これは、データ辞書やビジネス用語集の整備だけでなく、データとビジネスコンテキスト間の関係性をAIが理解できる形で表現する作業を含みます。AWS Glueのようなサービスで自動カタログ化を基盤としつつ、ビジネスドメインの専門家と連携して、データの意味論を深く定義し、セマンティックグラフや知識グラフといった形式でAIに提供するアプローチが、AIの「理解力」を飛躍的に向上させます。
-
金融規制とAIガバナンスへの早期対応: 金融業界のような高度に規制された環境でAIを導入する際、セキュリティとコンプライアンスは後回しにできない要素です。Amazon Bedrock Guardrailsのような専用サービスを初期段階からアーキテクチャに組み込むことで、AIの入出力に対する厳密な統制、機密データ保護、ログ記録、アクセス制御を実現し、規制要件への適合と監査対応を確実にします。開発者は、単に機能的な側面だけでなく、AIシステムのライフサイクル全体にわたるガバナンスとセキュリティの要件を初期設計フェーズから織り込み、コンプライアンスチームとの継続的な協業体制を確立することが成功の鍵となります。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。