DVCとAmazon SageMaker AI MLflowアプリによる機械学習モデルのエンドツーエンド系譜管理
エンドツーエンドのML系譜管理の必要性
機械学習(ML)モデルを本番環境で運用する際、モデルの学習に使用されたデータ、コード、実験メトリクスなど、その完全な系譜(リネージ)を追跡することは、多くのMLチームにとって大きな課題となっています。特に、規制の厳しい業界(医療、金融サービス、自動運転など)では、デプロイされたモデルがどの正確な学習データに基づいているかを監査要件として求められ、個々のレコードを将来の学習から除外する必要が生じる場合もあります。系譜管理が不十分な場合、「現在本番稼働中のモデルはどのデータで学習されたのか?」や「半年前にデプロイしたモデルを再現できるか?」といった基本的な問いへの回答が、散在したログやノートブック、Amazon S3バケットを何日もかけて調査する原因となります。この課題を解決し、モデルの再現性と説明責任を確保するためには、データ、コード、実験を一元的に管理し、リンクするエンドツーエンドの系譜管理ソリューションが不可欠です。
DVC、SageMaker AI、MLflow Appの統合アーキテクチャ
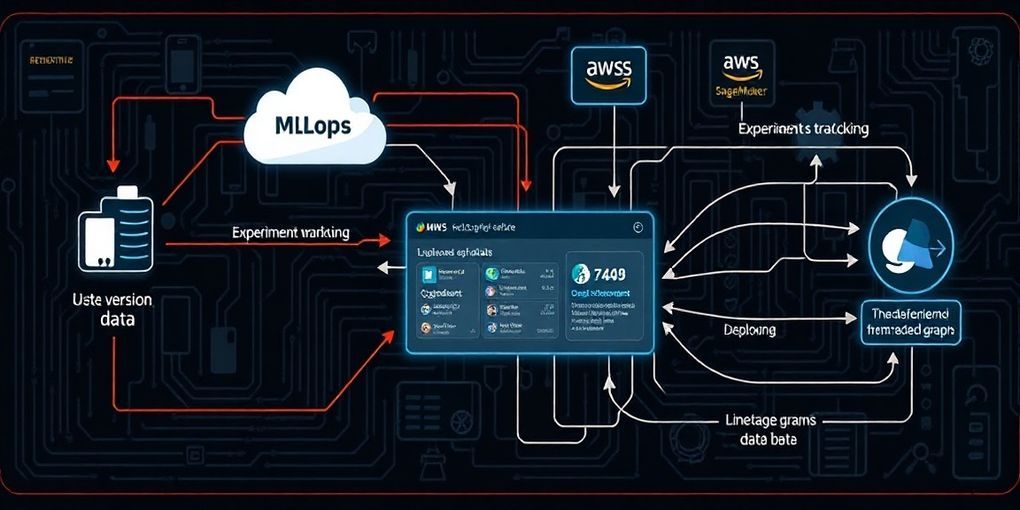
この課題を解決するため、AWSはDVC (Data Version Control)、Amazon SageMaker AI、そしてAmazon SageMaker AI MLflow Appを組み合わせた統合アーキテクチャを提案しています。この連携により、あらゆるモデルがその正確な学習データにまで遡って追跡可能となり、エンドツーエンドのMLワークフローにおける完全な再現性と透明性が実現されます。
-
DVCによるデータおよびアーティファクトのバージョン管理: DVCは、データセットやその他のMLアーティファクトのバージョン管理を担当します。Gitリポジトリには軽量な
.dvcメタファイルが格納され、実際のデータはAmazon S3のようなオブジェクトストレージに保存されます。これにより、Gitのコミットハッシュを通じて、モデルが学習に使用したデータセットの正確なバージョンを特定し、dvc pullコマンドを用いて再現することが可能になります。DVCの利用により、データ変更履歴の追跡とデータセットの再現性が保証されます。 -
Amazon SageMaker AIによるスケーラブルなML処理: Amazon SageMaker AIは、データ処理、モデル学習、モデルデプロイメントのためのスケーラブルな計算リソースとオーケストレーション機能を提供します。SageMakerの処理ジョブや学習ジョブは、DVCでバージョン管理されたデータを利用し、MLflow Appを通じてその実行状況が追跡されます。SageMakerは、MLモデルの迅速な構築、学習、デプロイを支援するフルマネージドサービスであり、インフラストラクチャの管理負担を軽減します。
-
Amazon SageMaker AI MLflow Appによる実験追跡とモデルレジストリ: Amazon SageMaker AI MLflow Appは、SageMaker Studio内で利用可能なフルマネージドサービスであり、実験追跡、モデルレジストリ、および系譜管理の核となります。各学習実行におけるパラメータ、メトリクス、アーティファクトを記録し、モデルのバージョン管理とライフサイクルステージ管理を可能にします。特に重要なのは、MLflowがDVCのコミットハッシュを記録することで、モデルを学習データセットの特定のバージョンと直接リンクさせる点です。これにより、MLflow上で登録されたモデルが、どのデータで、どのようなコードとパラメータで学習されたのか、一目で把握できるエンドツーエンドの系譜が確立されます。また、サーバーレス機能により、インフラストラクチャのプロビジョニングや追跡サーバーの設定が不要となり、より迅速な実験開始を可能にします。
データ系譜の2つのパターン:データセットレベルとレコードレベル
DVCとSageMaker AI MLflow Appを組み合わせることで、データの系譜を管理する2つの主要なパターンが実現されます。これらのパターンは、プロジェクトの要件に応じて柔軟に選択、または組み合わせて利用できます。
-
データセットレベルの系譜: このパターンでは、学習済みモデルを、それが学習されたデータセットの正確なバージョンに紐付けます。MLflowに記録されたDVCコミットハッシュを介して、モデルが使用したAmazon S3上の処理済みデータセットの特定の時点を再現することができます。例えば、CIFAR-10データセットの5%で学習し、その後10%に拡張して再学習するシナリオにおいて、DVCが各データセットバージョンを管理し、MLflowが各モデルを対応するデータバージョンにリンクさせます。これにより、「このモデルはどのデータセットバージョンで学習されたか?」という問いに答えることが可能になりますが、個々のレコードの内容に関する構造化されたメタデータは提供されません。
-
レコードレベルの系譜: データセットレベルの系譜をさらに強化したのが、レコードレベルの系譜です。このパターンでは、各データセットバージョン内の個々のレコードを詳細にインデックス化したマニフェストを追加します。このマニフェストをMLflowにログとして記録することで、「この特定のモデルはどの個々のレコードで学習されたか?」という問いに答えることが可能になります。これは、データオプトアウト要求や厳格な監査要件を満たす必要がある医療などの規制業界において特に重要です。マニフェストパターンを実装することで、個々のデータレコードの取り込み、変換、モデル学習への利用状況を詳細に追跡し、特定のレコードがモデル学習に与えた影響を分析することが可能になります。
MLOps実践者が考察すべき開発者インサイト
-
MLOpsパイプラインにおけるデータ主権の確立とリスク管理の強化: DVC、SageMaker、MLflowの組み合わせは、単なるバージョン管理や実験追跡を超え、MLOpsパイプライン全体におけるデータ主権を確立します。モデルがデプロイされた後も、その学習に使用された生のデータから前処理ステップ、特徴量エンジニアリング、そして最終的な学習データセットに至るまでの全てのパスを追跡できるため、データの削除要求(例:GDPR、CCPA)への対応や、データバイアス、データドリフト発生時の根本原因特定を劇的に簡素化できます。これは特に、データセットの更新頻度が高いリアルタイムMLシステムや、厳格なデータコンプライアンスが求められるエンタープライズ環境において、開発者の運用負荷を大幅に軽減し、信頼性の高いMLシステム構築を可能にします。
-
「実験の再現性」から「プロダクションモデルの再構築保証」への進化: 従来のML実験追跡は、主に「どの実験が最良の結果を出したか」を特定し、その実験を再現することに焦点を当てていました。しかし、この統合ソリューションは、DVCによるデータセットのImmutableなバージョン管理とMLflowによるその追跡を通じて、「現在プロダクションにあるモデルと全く同じものをいつでも再構築できる」という、より強力な保証を開発者に提供します。これは、セキュリティパッチの適用やフレームワークのバージョンアップ、あるいはA/Bテスト後のロールバックなど、本番環境での運用時にモデルの安定性と信頼性を維持するために不可欠な能力となります。開発者は、自信を持ってモデルの変更や更新を進めることができるようになります。
-
データ中心型AI開発を加速する強力な基盤: このエンドツーエンドの系譜管理は、データ中心型AI (Data-centric AI) 開発パラダイムへの移行を強力に推進する基盤となります。モデルの性能向上において、アルゴリズムの改善だけでなく、データの品質や特性の改善が重要視される中、DVCとMLflowの組み合わせは、異なるデータバージョンがモデル性能にどのような影響を与えたかを詳細に分析するための明確なメカニズムを提供します。開発者は、特定のデータクリーニング戦略やデータ拡張手法が、モデルの特定の層や挙動にどう影響したかを容易に検証でき、データセットの改善に焦点を当てた、より効率的かつ効果的なAI開発サイクルを構築できるようになります。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。