Amazon Nova MicroとBedrockオンデマンド推論による費用対効果の高いカスタムText-to-SQL
Amazon Nova Microを活用したText-to-SQLの費用対効果
Amazon Nova Microは、AmazonのNovaファミリーに属するテキスト専用モデルであり、Text-to-SQLソリューションにおいて費用対効果と高速な応答を両立させる主要な要素として注目されています。このモデルは、Novaファミリーの中で最も低いレイテンシと推論あたりの最低コストを実現するように最適化されています。Text-to-SQLのようなタスクでは、ユーザーの自然言語クエリをSQL文に変換する必要があり、このプロセスにおいてNova Microの低コストかつ高速な処理能力が全体的な運用コストの削減に大きく貢献します。
Nova Microは、128Kトークンという十分なコンテキストウィンドウを持ち、要約、翻訳、分類、インタラクティブチャット、および基本的なコーディングタスクに優れています。Text-to-SQLの文脈では、特にシンプルなクエリの生成や、データベーススキーマのメタデータからの関連情報抽出において、その効率性が発揮されます。複雑なマルチモーダル機能が不要なText-to-SQLのシナリオでは、Nova Microを選択することで、より高性能なモデルを使用する場合と比較して、推論コストを大幅に削減できるという利点があります。これは、特に大規模なエンタープライズ環境で頻繁なクエリが実行される場合に、顕著な費用削減につながります。
Amazon Bedrockオンデマンド推論によるスケーラブルなText-to-SQL構築
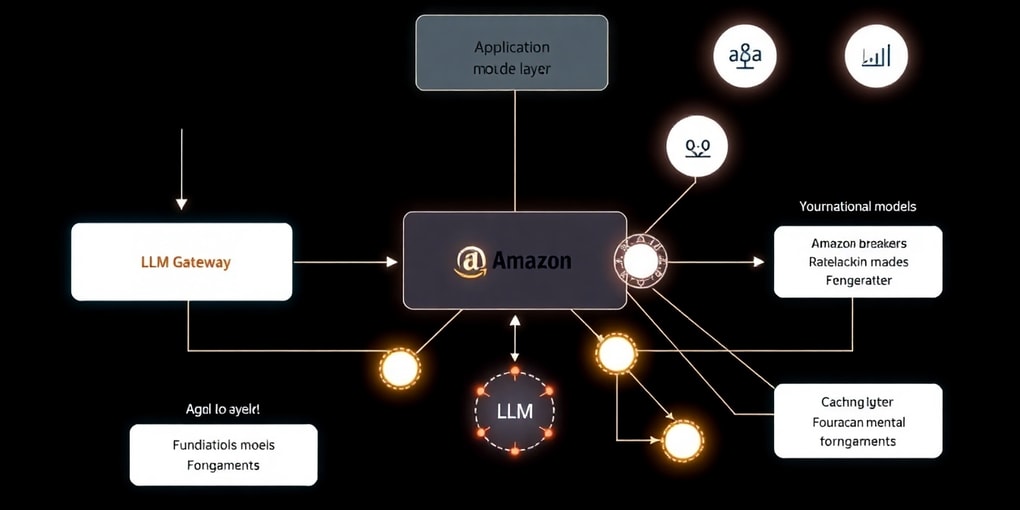
Amazon Bedrockは、Anthropic、Cohere、Meta、Mistral AI、Stability AI、そしてAmazonといった主要なAI企業が提供する高性能な基盤モデル(FM)に単一のAPIを通じてアクセスできるフルマネージドサービスです。Text-to-SQLソリューションにおいて、Bedrockのオンデマンド推論は、必要なときに必要なだけリソースを使用できるため、予測不能なワークロードや変動の大きい需要に対して、高いスケーラビリティと費用対効果を提供します。
Text-to-SQLソリューションのアーキテクチャでは、通常、Bedrock Agentsが中心的な役割を果たします。Agentはユーザーのリクエストを理解し、複雑なタスクを複数のステップに分解し、アクションを実行してユーザーの要求を満たします。具体的には、自然言語クエリをSQLに変換し、Amazon AthenaやAmazon Redshiftのようなデータベースに対して実行し、結果を自然言語で返すことができます。Bedrock Agentsは、動的なスキーマディスカバリ機能を通じて、データベースの構造変更に自動的に適応し、リアルタイムで最新のデータベース構造を反映したSQLを生成します。さらに、クエリ実行が失敗した場合、Agentはエラーメッセージを自律的に分析し、クエリを修正して再試行する堅牢なエラーハンドリング能力も備えています。これにより、手動による更新作業が不要となり、運用上のオーバーヘッドが削減され、パフォーマンスと費用対効果が向上します。
Bedrockを利用したText-to-SQLソリューションでは、Nova Microのようなコスト効率の高いモデルを特定のタスク(例:シンプルなクエリの生成、応答の整形)に割り当て、より複雑な推論やマルチモーダル機能が必要な場面ではNova ProやNova Liteといった高性能モデルを利用することで、全体のコストと性能のバランスを最適化できます。
エンタープライズ向けカスタムText-to-SQLの実装と最適化
エンタープライズ環境におけるText-to-SQLソリューションの実装には、単なる自然言語からSQLへの変換以上の考慮事項が求められます。特に、100を超えるテーブルと数十の列を持つ複雑なデータベース構造、ドメイン固有の専門用語、および組織固有のビジネスロジックに対応するためには、カスタムText-to-SQLアプローチが不可欠です。
カスタムText-to-SQLソリューションの鍵は、正確なスキーマ情報とビジネスコンテキストの提供です。モデルをスキーマ固有のメタデータ(テーブル名、列のヒント、サンプルクエリ)でトレーニングすることで、精度が劇的に向上します。Amazon DataZoneのようなデータ管理システムは、部門間のデータ発見を民主化し、複数のソースからのビジネスデータをカタログ化することで、正確なText-to-SQL変換に必要なコンテキストを供給します。
また、Text-to-SQLソリューションは、以下の最適化を通じてその価値を最大化できます。
-
動的スキーマコンテキストの利用: データベーススキーマを動的に取得し、Text-to-SQLシステムにシームレスに統合することで、手動での作業を削減し、スケーラビリティを向上させます。これにより、データベースの変更にも柔軟に対応できます。
-
RAG (Retrieval-Augmented Generation) の活用: 関連するテーブルスキーマやドキュメントを検索し、プロンプトに含めることで、LLMの推論精度を向上させ、より小さなコンテキストウィンドウを持つLLMの使用を可能にし、結果としてレイテンシとコストを削減します。
-
自律的なトラブルシューティングとエラーハンドリング: 生成されたSQLクエリの実行が失敗した場合、Agentがエラーメッセージを分析し、クエリを修正して再試行するメカニズムは、Text-to-SQLソリューションの信頼性と成功率を高める上で極めて重要です。
開発者・エンジニア視点での考察
-
モデル選択とコスト最適化の戦略的アプローチ: Text-to-SQLソリューションを設計する際、単一の高性能LLMに依存するのではなく、タスクの複雑性に応じてAmazon Nova Microのような費用対効果の高いモデルと、Nova Pro/Liteのような高性能モデルを組み合わせるマルチモデル戦略が有効です。シンプルな情報抽出や簡単なクエリ生成にはNova Micro、複雑な結合や集計を伴うクエリ、あるいはエラー修正にはより高性能なモデルを利用することで、全体の運用コストを最適化しつつ、パフォーマンス要件を満たすことができます。
-
動的スキーマ管理とRAGによる精度向上: エンタープライズのデータベースは常に変化します。Text-to-SQLの精度を維持するためには、静的なスキーマ定義に依存するのではなく、動的に最新のデータベーススキーマを取得し、それをRAGの一部としてLLMのプロンプトに組み込む仕組みが不可欠です。これにより、LLMが常に最新かつ正確なデータベース構造に基づいてSQLを生成できるようになり、“構文は正しいが意味的に無用な”クエリの生成リスクを低減し、開発者のメンテナンス負荷を軽減します。
-
エージェントによる自律的エラーハンドリングの設計思想: ユーザーが自然言語でデータにアクセスする際、SQL生成や実行の失敗は避けられません。Amazon Bedrock Agentsが提供する自律的なエラー分析と修正の機能は、Text-to-SQLソリューションのユーザーエクスペリエンスを劇的に向上させます。開発者は、単にエラーメッセージを返すだけでなく、LLMにエラーメッセージを解釈させ、クエリ修正を試みるフローを組み込むことで、より堅牢でユーザーフレンドリーなデータ探索ツールを構築できます。これは、非技術系ユーザーがデータ分析を自己完結できる度合いを高める上で極めて重要です。
Source / 元記事
この記事について
この記事は、公開されているニュース、論文、公式発表、RSSフィードなどをもとに、AIが要約・補足調査・考察を行って作成しています。
元記事の完全な翻訳・逐語的な要約ではなく、AIによる背景説明や開発者向けの考察を含みます。
重要な技術仕様・価格・提供状況などは、必ず元記事または公式情報をご確認ください。